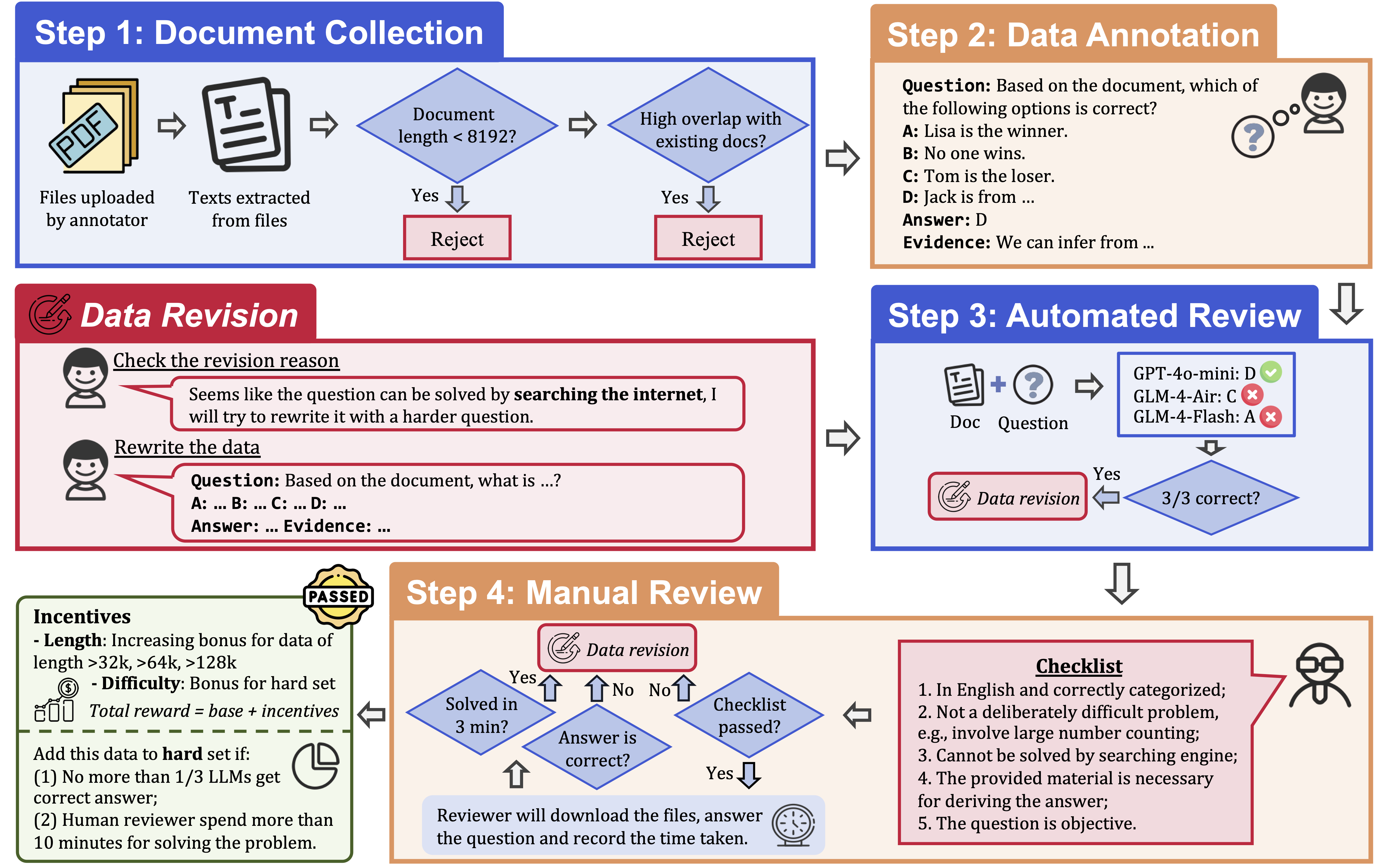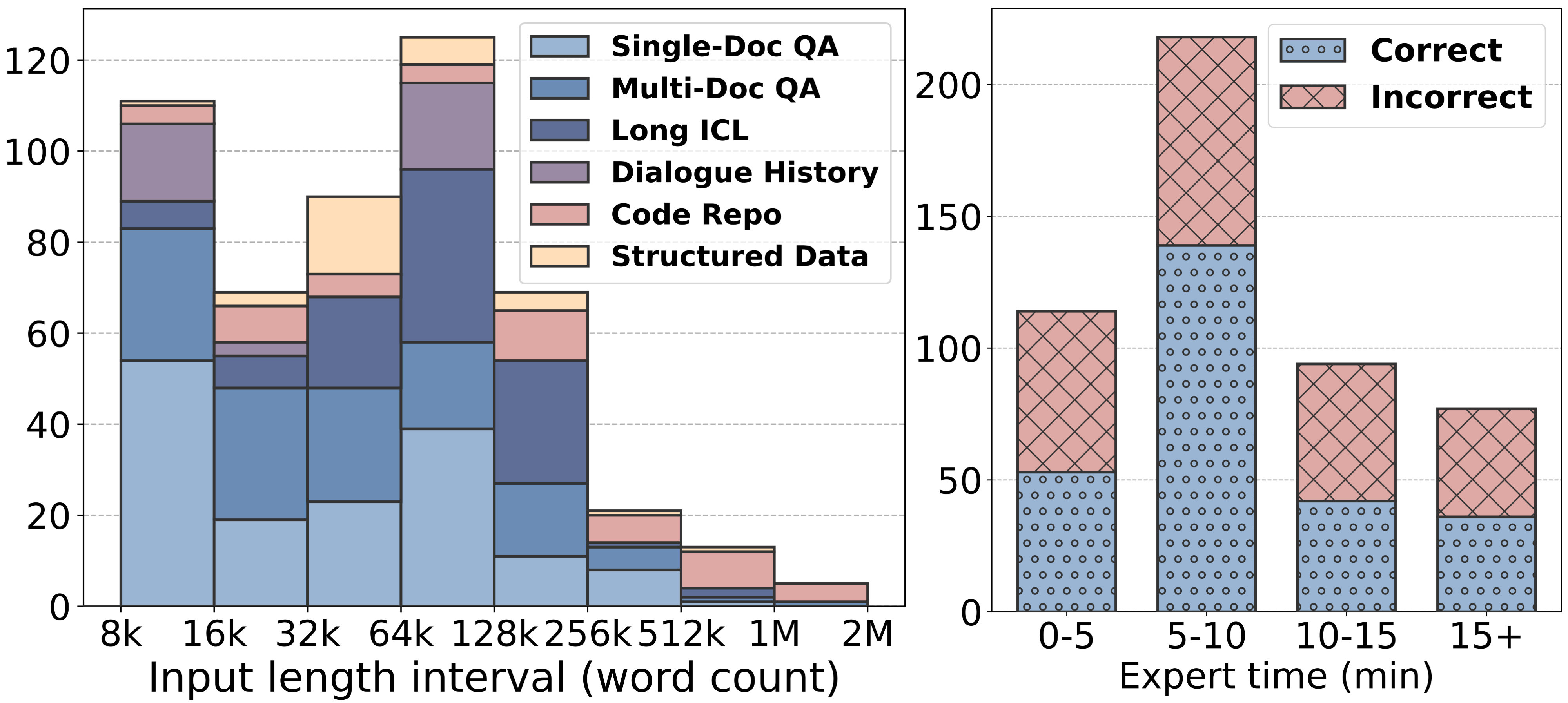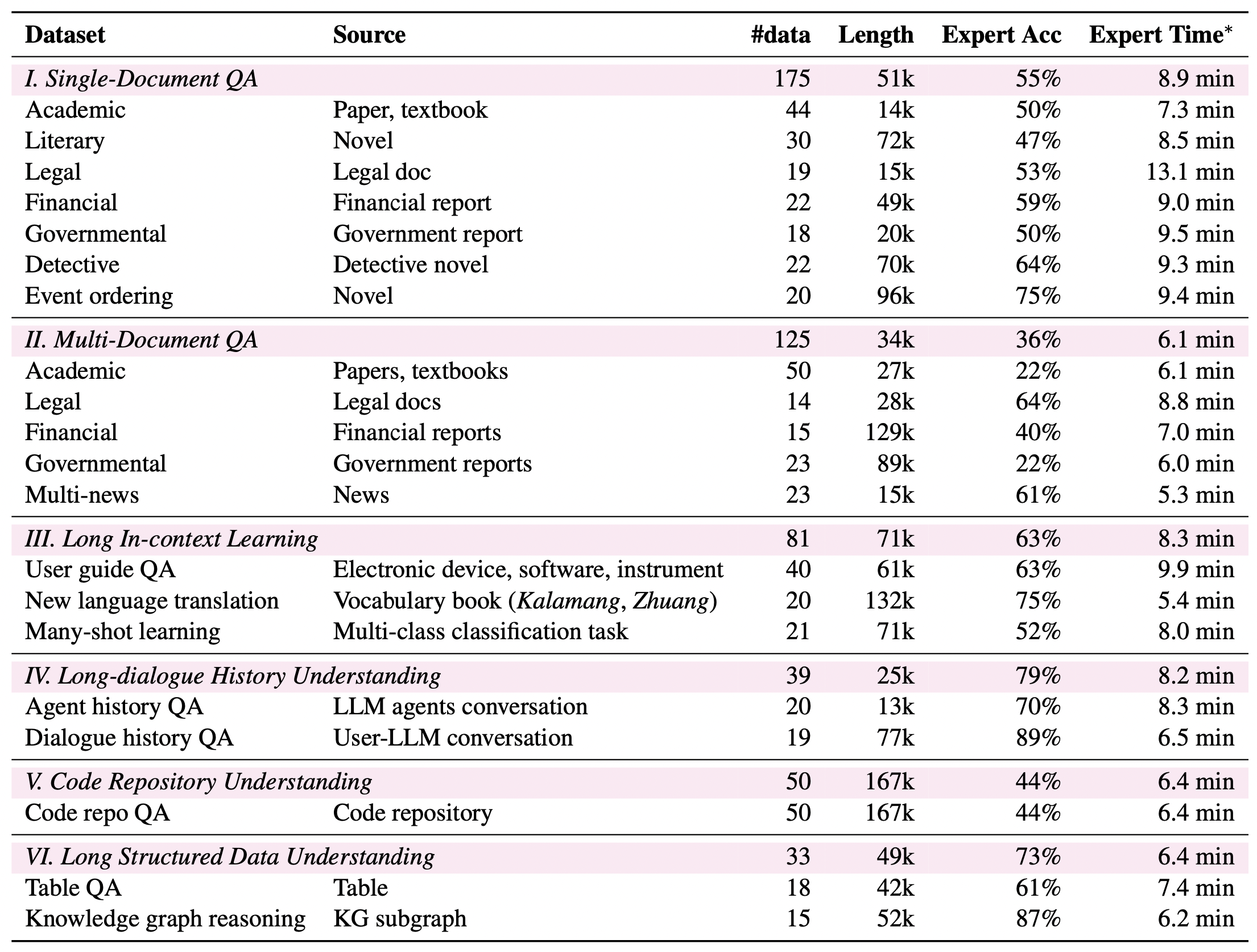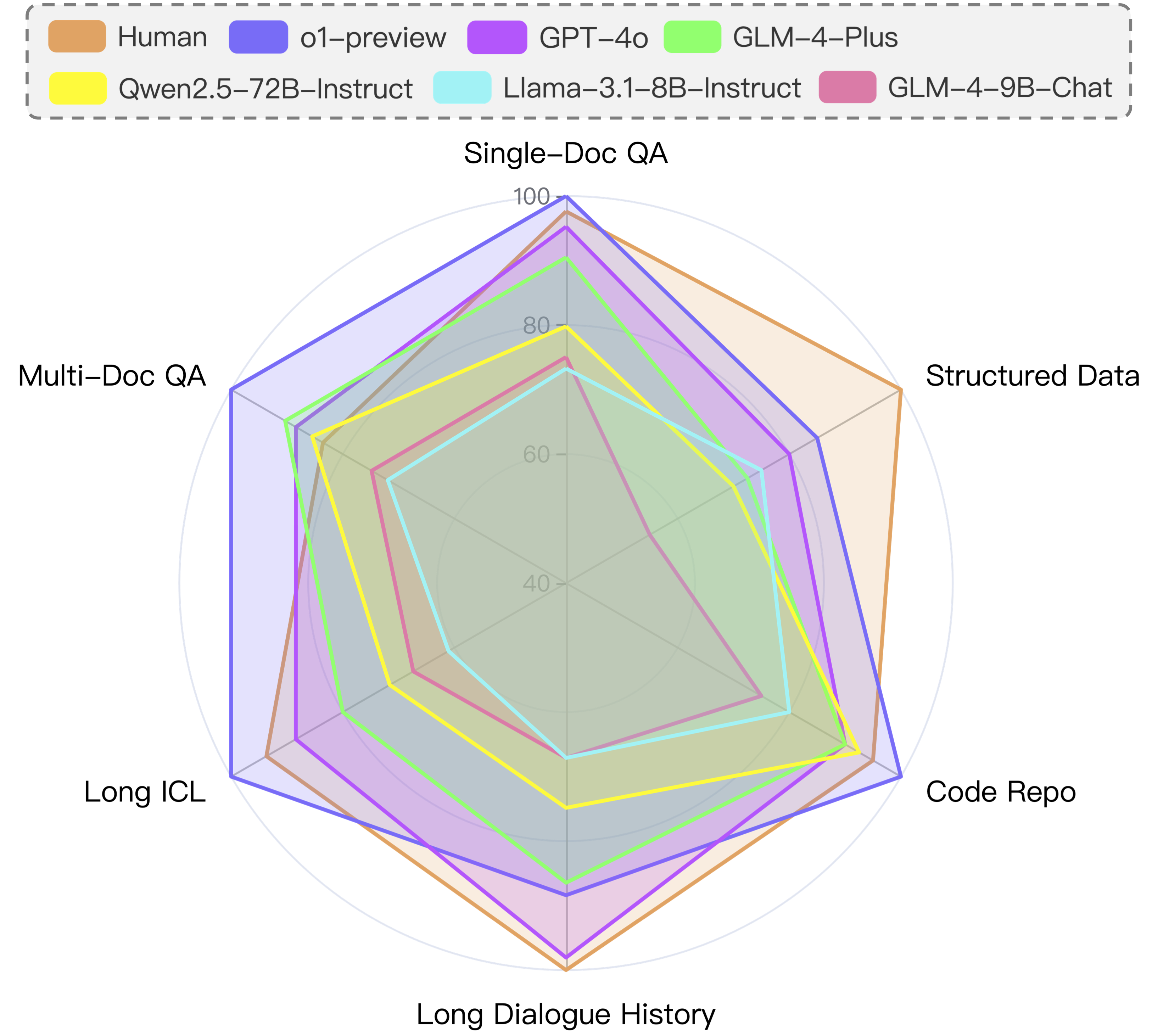
📢 The leaderboard is constantly updating as we are welcoming new submissions!
We consider two test settings: w/o CoT and w/ CoT.
Short: 0 ~ 32k words Medium: 32k ~ 128k words Long: 128k ~ 2M words
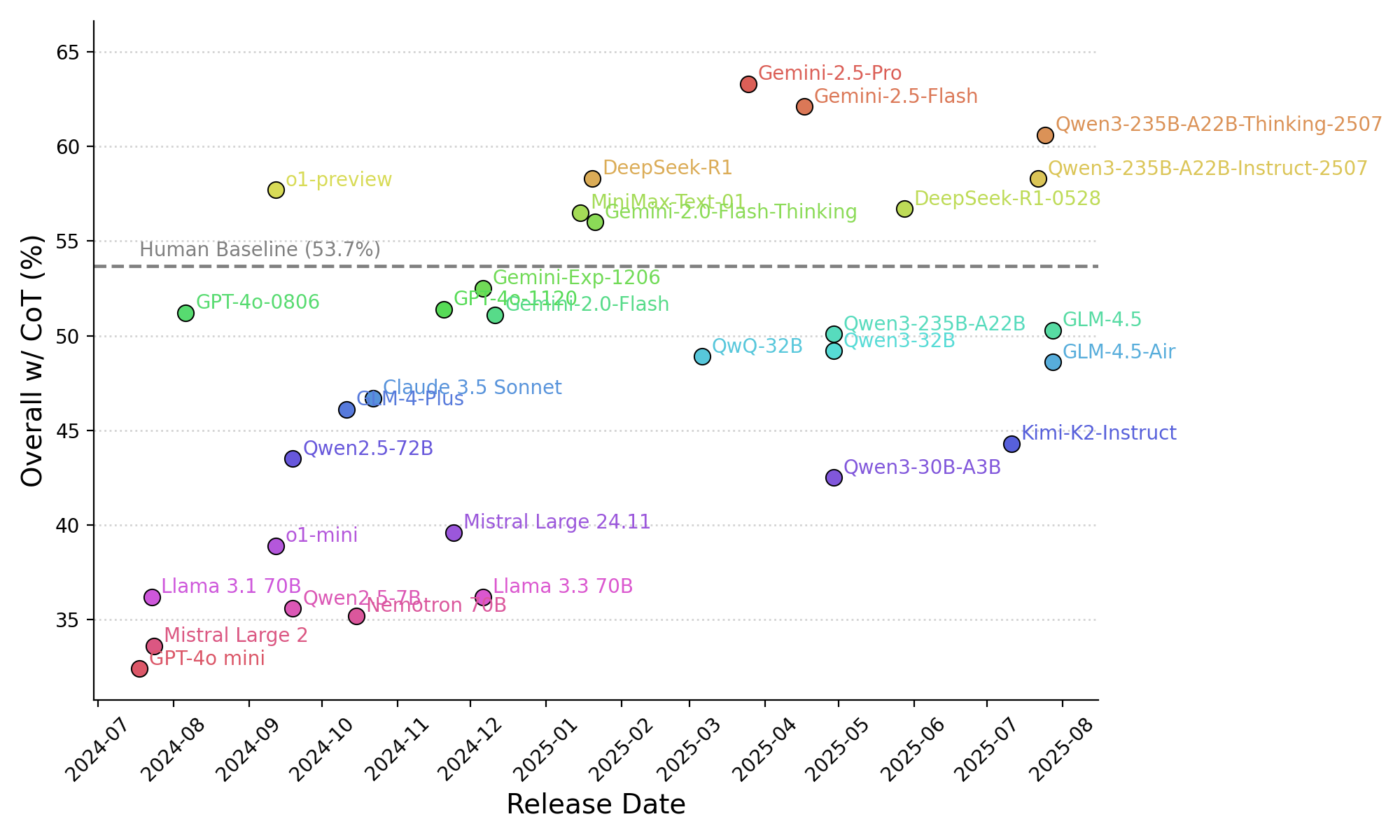
By default, this leaderboard is sorted by the overall accuracy w/ CoT, as reasoning models (indicated by 🧠) natively use CoT to answer questions. The CoT results for non-reasoning models are obtained using our prompt that enforces the model to first generate the CoT and then the final answer. To view other sorted results, please click on the corresponding cell.
| # | Model | Params | Context | Date | Overall (%) | Easy (%) | Hard (%) | Short (%) | Medium (%) | Long (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| w/ CoT | w/ CoT | w/ CoT | w/ CoT | w/ CoT | w/ CoT | |||||||||||
|
Gemini-2.5-Pro🧠
|
- | 1M | 2025-03-25 |
- | 63.3 | - | 75.0 | - | 56.1 | - | 67.2 | - | 56.3 | - | 71.0 | |
|
Gemini-2.5-Flash🧠
|
- | 1M | 2025-04-17 |
- | 62.1 | - | 72.3 | - | 55.8 | - | 68.3 | - | 60.0 | - | 55.7 | |
| Qwen3-235B-A22B-Thinking-2507🧠 Alibaba |
235B | 256k | 2025-07-25 |
- | 60.6 | - | 70.5 | - | 54.4 | - | 62.8 | - | 59.9 | - | 58.1 | |
|
DeepSeek-R1🧠
DeepSeek |
671B | 128k | 2025-01-20 |
- | 58.3 | - | 66.1 | - | 53.4 | - | 62.2 | - | 54.4 | - | 59.3 | |
| Qwen3-235B-A22B-Instruct-2507 Alibaba |
235B | 256k | 2025-07-22 |
46.7 | 58.3 | 51.6 | 66.7 | 43.7 | 53.1 | 52.2 | 63.3 | 44.2 | 55.3 | 42.6 | 55.6 | |
|
o1-preview🧠
OpenAI |
- | 128k | 2024-09-12 | - | 57.7 | - | 66.8 | - | 52.1 | - | 62.6 | - | 53.5 | - | 58.1 | |
|
DeepSeek-R1-0528🧠
DeepSeek |
671B | 128k | 2025-05-28 |
- | 56.7 | - | 59.4 | - | 55.0 | - | 66.7 | - | 50.9 | - | 51.4 | |
|
MiniMax-Text-01
MiniMax |
456B | 4M | 2025-01-15 |
52.9 | 56.5 | 60.9 | 66.1 | 47.9 | 50.5 | 58.9 | 61.7 | 52.6 | 56.7 | 43.5 | 47.2 | |
|
Gemini-2.0-Flash-Thinking🧠
|
- | 1M | 2025-01-21 |
- | 56.0 | - | 62.8 | - | 51.9 | - | 61.1 | - | 55.2 | - | 49.1 | |
| Human | N/A | N/A | N/A | 53.7 | 53.7 | 100 | 100 | 25.1 | 25.1 | 47.2 | 47.2 | 59.1 | 59.1 | 53.7 | 53.7 | |
|
Gemini-Exp-1206
|
- | 2M | 2024-12-06 |
49.3 | 52.5 | 52.9 | 61.5 | 47.1 | 47.1 | 53.9 | 55.6 | 47.1 | 49.5 | 45.8 | 53.3 | |
|
GPT-4o
OpenAI |
- | 128k | 2024-11-20 |
46.0 | 51.4 | 50.8 | 54.2 | 43.0 | 49.7 | 47.5 | 59.6 | 47.9 | 48.6 | 39.8 | 43.5 | |
|
GPT-4o
OpenAI |
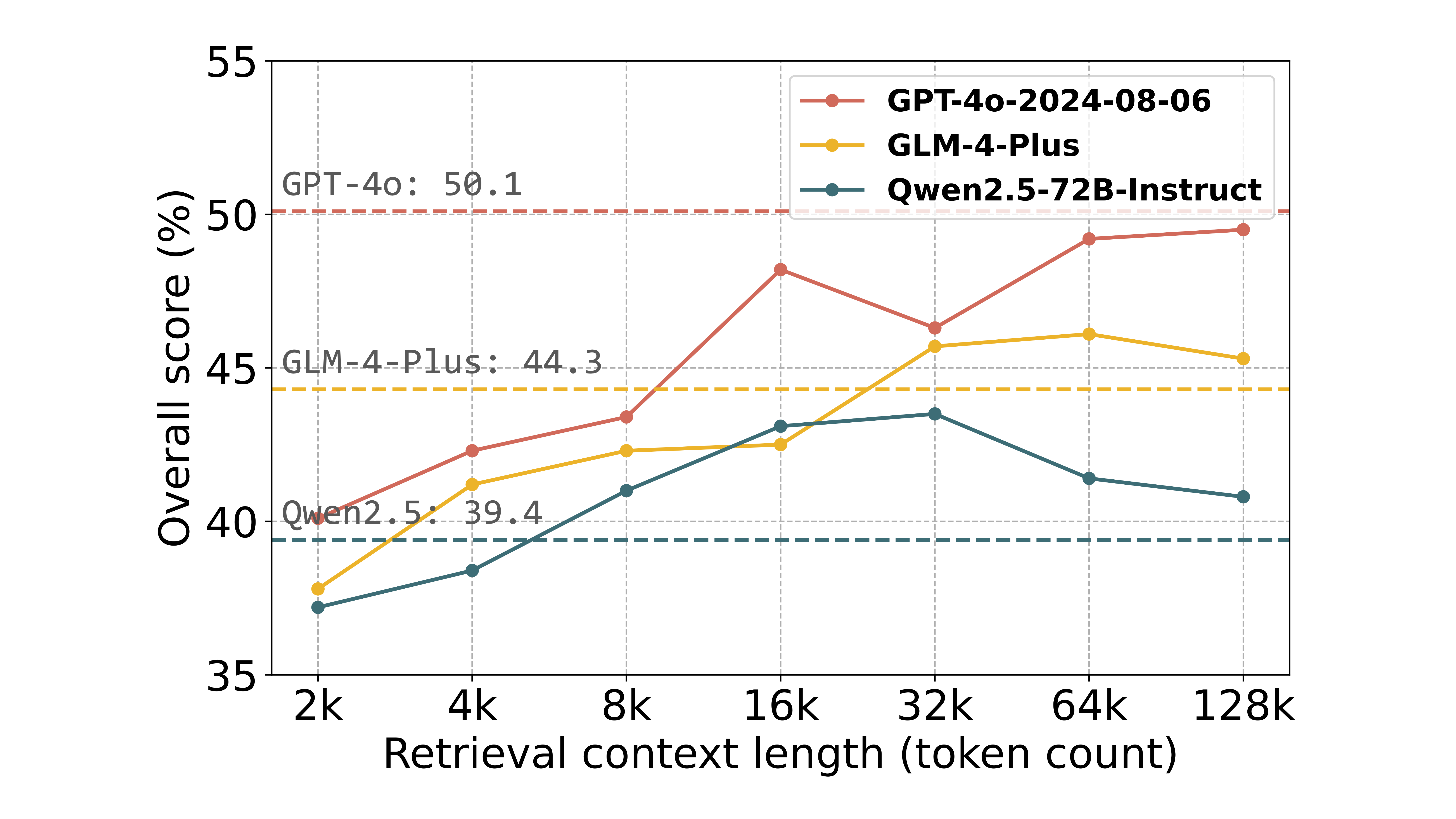
- | 128k | 2024-08-06 | 50.1 | 51.2 | 57.4 | 57.9 | 45.6 | 47.1 | 53.3 | 53.9 | 52.4 | 50.7 | 40.2 | 47.7 | |
|
Gemini-2.0-Flash
|
- | 1M | 2024-12-11 |
47.4 | 51.1 | 51.0 | 58.3 | 45.2 | 46.6 | 48.9 | 57.2 | 47.7 | 45.3 | 44.4 | 52.3 | |
| GLM-4.5🧠 Z.ai & Tsinghua |
355B | 128k | 2025-07-28 |
- | 50.3 | - | 57.8 | - | 45.7 | - | 57.8 | - | 44.2 | - | 50.0 | |
| Qwen3-30B-A3B-Thinking-2507🧠 Alibaba |
30B | 256k | 2025-07-25 |
- | 50.1 | - | 58.9 | - | 44.7 | - | 56.7 | - | 46.0 | - | 47.2 | |
| Qwen3-235B-A22B🧠 Alibaba |
235B | 128k | 2025-04-29 |
40.4 | 50.1 | 47.4 | 56.4 | 36.0 | 46.2 | 45.6 | 58.3 | 36.7 | 44.1 | 38.9 | 48.6 | |
| Qwen3-32B🧠 Alibaba |
32B | 128k | 2025-04-29 |
38.8 | 49.2 | 42.2 | 53.1 | 36.7 | 46.8 | 40.6 | 60.0 | 38.1 | 41.1 | 37.0 | 47.2 | |
| QwQ-32B🧠 Alibaba |
32B | 128k | 2025-03-06 |
- | 48.9 | - | 58.9 | - | 42.8 | - | 54.4 | - | 44.7 | - | 48.1 | |
| GLM-4.5-Air🧠 Z.ai & Tsinghua |
106B | 128k | 2025-07-28 |
- | 48.6 | - | 54.7 | - | 44.8 | - | 58.9 | - | 41.9 | - | 44.9 | |
| Claude 3.5 Sonnet
Anthropic |
- | 200k | 2024-10-22 | 41.0 | 46.7 | 46.9 | 55.2 | 37.3 | 41.5 | 46.1 | 53.9 | 38.6 | 41.9 | 37.0 | 44.4 | |
| GLM-4-Plus
Z.ai & Tsinghua |
- | 128k | 2024-10-11 | 44.3 | 46.1 | 47.4 | 52.1 | 42.4 | 42.4 | 50.0 | 53.3 | 46.5 | 44.7 | 30.6 | 37.0 | |
| Kimi-K2-Instruct
Moonshot AI |
1T | 128k | 2025-07-11 |
44.9 | 44.3 | 50.0 | 49.5 | 41.8 | 41.2 | 51.7 | 52.2 | 39.1 | 38.1 | 45.4 | 43.5 | |
| Qwen2.5-72B
Alibaba |
72B | 128k | 2024-09-19 | 42.1 | 43.5 | 42.7 | 47.9 | 41.8 | 40.8 | 45.6 | 48.9 | 38.1 | 40.9 | 44.4 | 39.8 | |
| Qwen3-30B-A3B🧠 Alibaba |
30B | 128k | 2025-04-29 |
32.6 | 42.5 | 34.4 | 47.8 | 31.5 | 39.3 | 35.0 | 52.0 | 32.1 | 36.0 | 29.6 | 39.8 | |
| Mistral Large 24.11
Mistral AI |
123B | 128k | 2024-11-24 | 34.4 | 39.6 | 38.0 | 43.8 | 32.2 | 37.0 | 41.7 | 46.1 | 30.7 | 34.9 | 29.6 | 38.0 | |
| o1-mini
OpenAI |
- | 128k | 2024-09-12 | 37.8 | 38.9 | 38.9 | 42.6 | 37.1 | 36.6 | 48.6 | 48.9 | 33.3 | 32.9 | 28.6 | 34.3 | |
| Llama 3.1 70B
Meta |
70B | 128k | 2024-07-23 | 31.6 | 36.2 | 32.3 | 35.9 | 31.2 | 36.3 | 41.1 | 45.0 | 27.4 | 34.0 | 24.1 | 25.9 | |
| Llama 3.3 70B
Meta |
70B | 128k | 2024-12-06 | 29.8 | 36.2 | 34.4 | 38.0 | 27.0 | 35.0 | 36.7 | 45.0 | 27.0 | 33.0 | 24.1 | 27.8 | |
| Qwen2.5-7B
Alibaba |
7B | 128k | 2024-09-19 | 30.0 | 35.6 | 30.7 | 38.0 | 29.6 | 34.1 | 40.6 | 43.9 | 24.2 | 32.6 | 24.1 | 27.8 | |
| Nemotron 70B
Nvidia |
70B | 128k | 2024-10-15 | 31.0 | 35.2 | 32.8 | 37.0 | 29.9 | 34.1 | 38.3 | 46.7 | 27.9 | 29.8 | 25.0 | 26.9 | |
| Mistral Large 2
Mistral AI |
123B | 128k | 2024-07-24 | 26.6 | 33.6 | 29.7 | 34.4 | 24.8 | 33.1 | 37.8 | 41.1 | 19.5 | 31.2 | 22.2 | 25.9 | |
| GPT-4o mini
OpenAI |
- | 128k | 2024-07-18 | 29.3 | 32.4 | 31.1 | 32.6 | 28.2 | 32.2 | 31.8 | 34.8 | 28.6 | 31.6 | 26.2 | 29.9 | |
| NExtLong 8B CAS |
8B | 512k | 2025-01-23 |
30.8 | 32.0 | 33.9 | 36.5 | 28.9 | 29.3 | 37.8 | 37.2 | 27.4 | 31.2 | 25.9 | 25.0 | |
| Command R+
Cohere |
104B | 128k | 2024-08-30 | 27.8 | 31.6 | 30.2 | 34.4 | 26.4 | 29.9 | 36.7 | 39.4 | 23.7 | 24.2 | 21.3 | 33.3 | |
| GLM-4-9B
Z.ai & Tsinghua |
9B | 128k | 2024-06-05 | 30.2 | 30.8 | 30.7 | 34.4 | 29.9 | 28.6 | 33.9 | 35.0 | 29.8 | 30.2 | 25.0 | 25.0 | |
| Llama 3.1 8B
Meta |
8B | 128k | 2024-07-23 | 30.0 | 30.4 | 30.7 | 36.5 | 29.6 | 26.7 | 35.0 | 34.4 | 27.9 | 31.6 | 25.9 | 21.3 | |
| Random | N/A | N/A | N/A | 25.0 | 25.0 | 25.0 | 25.0 | 25.0 | 25.0 | 25.0 | 25.0 | 25.0 | 25.0 | 25.0 | 25.0 | |
Green date indicates the newly added/updated models - indicates closed-source models
1*. Human accuracy is based on their performance within a 15-minute time limit, after which they are allowed to respond with "I don’t know the answer". This occurred for 8% of the total test data. 2*. Humans achieve 100% accuracy on the 'Easy' subset because it only include questions that humans answer correctly within 10 mins. 3*. Models do not show lower scores on subsets with longer length ranges because the distribution of tasks differs significantly across each length range. 4*. The reported results of Qwen models are evaluated using YaRN with a scaling factor of 4. 5*. Qwen3 models support hybrid thinking. For the w/o CoT results, we evaluate them in non-thinking mode, and for the w/ CoT results, we use thinking mode with a 16K token thinking budget.
Last Update: 2025-05-06